Test your AI readiness with Opera’s new device benchmark tool
Share





One of the biggest bets we have is that AI will at least partially be done locally on your devices, and especially in your browser. This enables new use cases and can improve your privacy. On-device AI will, however, put your device to new tests. Today, for the first time, you can test how ready your device is to run AI directly on your device with our new devicetest.ai.
The test requires you to use the latest version of Opera Developer, which recently became the first browser that supports built-in local LLMs. When activated, the test will download an LLM and run several checks for things like tokens per second, first token latency, and model load time, before presenting how ready your device is for running on-device AI.
If you’re impatient like some of us and want to test whether your device is AI-ready right away, proceed straight to the test.
If you’d like some more information, keep reading.
Why is Opera releasing the first-ever on-device AI benchmarking tool?
That’s because we think it’s very important, and previously there just hasn’t been one. Over the course of our work on multiple AI solutions for our browsers, we realized that there’s not a real benchmarking tool for local LLMs that’s easily accessible for the general public. So whether you’re a casual AI user, an enthusiast with an over-the-top PC, or even a researcher trying to compare different LLMs, our benchmark tool will suit your needs.
How to use the AI Benchmarking tool
Let’s do a step-by-step guide to get the AI Benchmarking tool working:
- First, go to the following link – which you’ll need to open using Opera Developer!
- Then, read the relevant information and click on “Run Test.”
- Next, you’ll need to choose a profile to perform the test (don’t worry, we’ll explain).
- Click “Start Test.”
- The test will take a few minutes – the exact duration of it depends on your system’s specifications and the profile you chose. It can range from 3 to 20 minutes – we wouldn’t recommend trying it on a literal toaster. You can cancel it at any time.
- Once the test is completed you’ll see the results appear.
- You can share the results by copying the link provided at the end of the test.
- You can also download the results as a CSV file to use it for further analysis.
So, what are the profiles mentioned previously? This is an important step in the process – they basically refer to which local LLM will be downloaded and used to perform the test. There are three profiles available and each one represents an ever more resource-demanding local LLM. You’ll find the specific model and version used for each profile, as well as its download size.

The idea here is that you’ll choose a profile consistent with the hardware that you have at hand. It wouldn’t be a representative test to use a cutting-edge PC with the most basic profile, just as it wouldn’t make sense to have your kitchen toaster run a 13 billion parameter model. But no worries, this isn’t a red-pill or blue-pill kind of choice – you can always redo the test with a different profile.
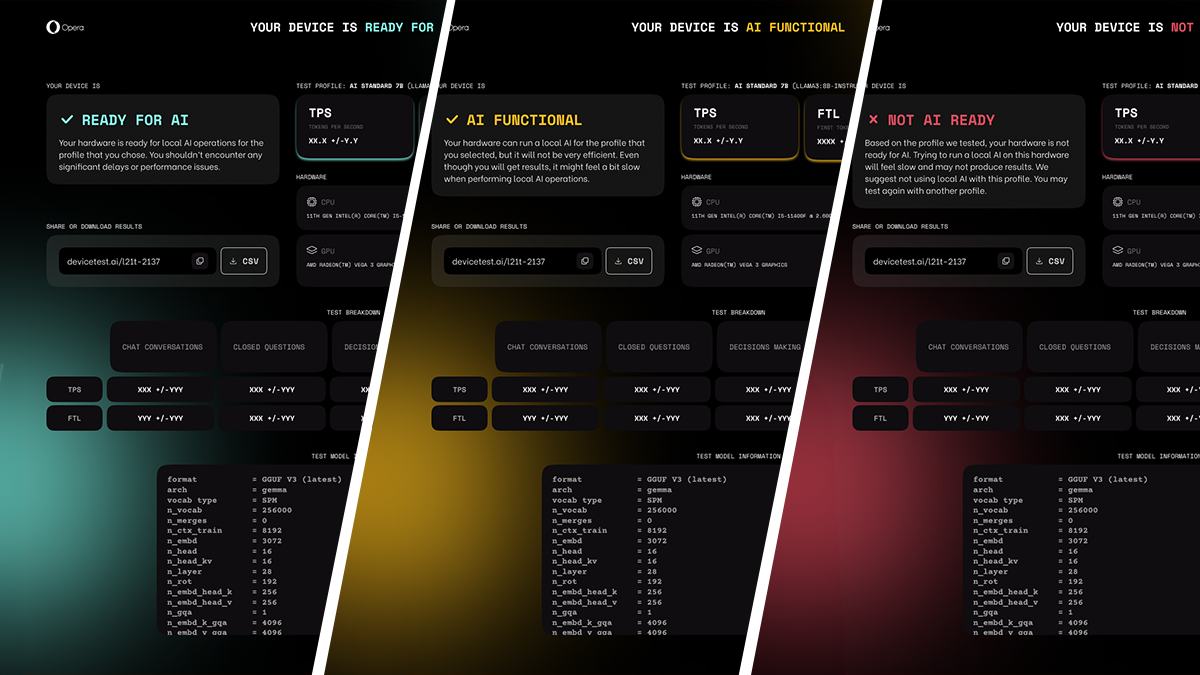
What do the color-coded results mean?
Once you’ve completed the test, a results page will appear. There’s a color coding to this page: Green means AI Ready, Yellow means AI Functional, and Red means Not AI Ready. But that’s just the beginning, there’s much more for you to dig into.
Let’s take a look at an example of a device that is AI ready:
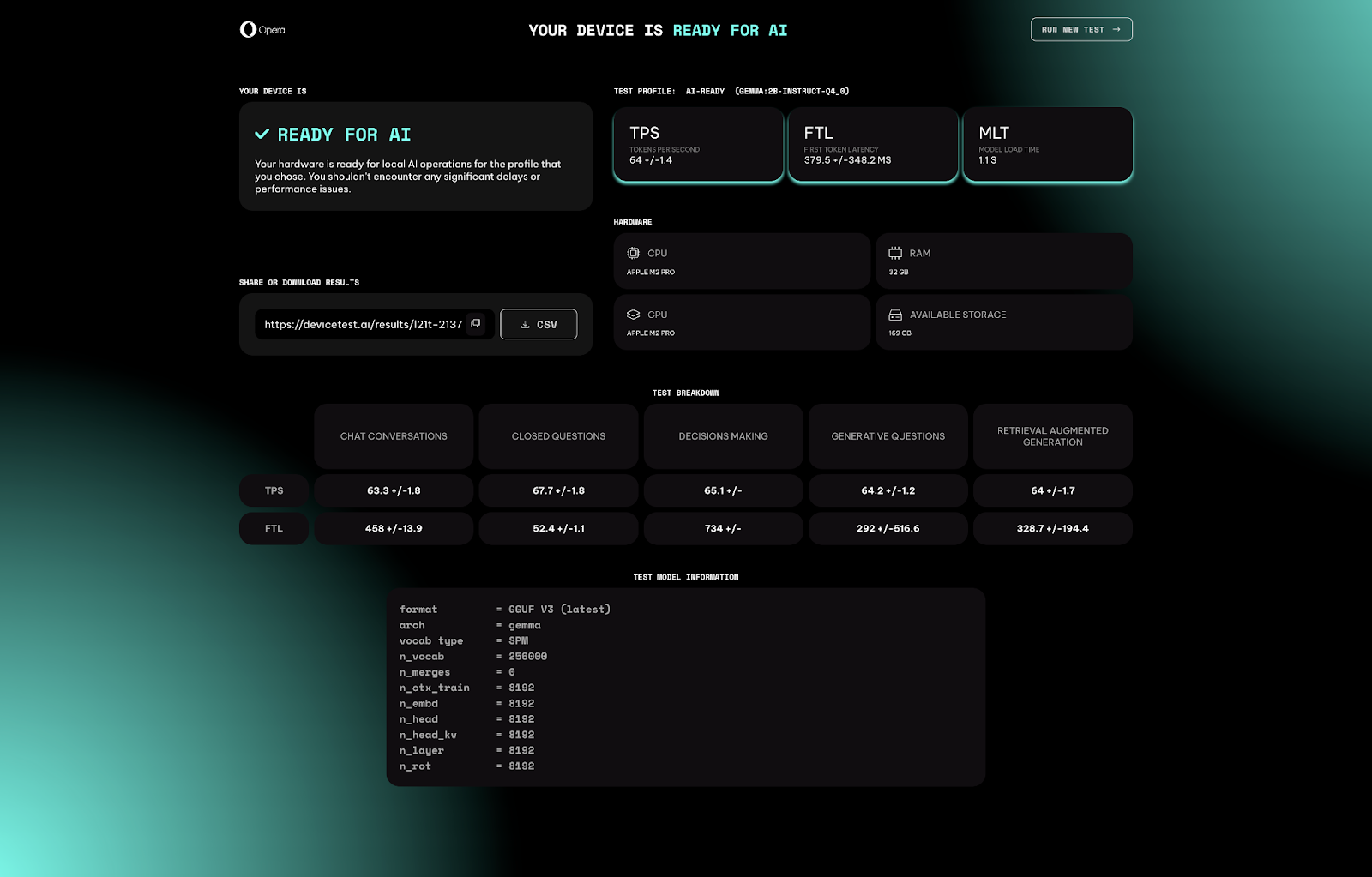
There’s three main indicators that we’ll be looking at when performing this test, and that will determine you device’s readiness for AI:
- Tokens Per Second (TPS): What’s a Token? Well, broadly speaking, LLMs often break down text into tokens as a first step in processing. Depending on the model, a token can be a word, or even a fraction of a word, and they become the building block of the LLM. In this case, it refers to ¾ of an average-length word. So, essentially this metric measures how many 4-character English words – including spaces – per second the LLM can process given your hardware. This is arguably the most important metric.
- First Token Latency (FTL): This metric measures the amount of time that it takes the model to generate the very first word after you give it a prompt. Local LLMs could potentially be faster than server-based LLMs because there’s no internet lag interfering.
- Model Load Time (MLT): This metric measures the amount of time that it takes for your hardware to load the LLM into your system’s RAM memory when you open it for the first time.
The benchmarking tool will perform a series of tasks using the AI model that you chose when selecting a profile. These tasks will be repeated several times for redundancy and to generate a significant result. The displayed result you get is the average of all the iterations.
As you can see, the benchmarking tool also identifies and shows you the system’s specs that are being put under stress during the test.
Additional results can be found below the system specs, and they refer to different AI tasks that a local LLM would typically perform. The model will execute these tasks several times and then provide the average TPS and FTL for each one of them. This gives you further insights into which ones your device can handle better.

At this point most of you AI enthusiasts should have a good idea of how your system performs when running local LLMs. However, for the engineers and hackermen out there – those unsung heroes that make AI a reality – there is even more information about the test under “Test Model Information.”
Share and Download your results
Remember that you can download the test results as a CSV file to use it for further analysis. Likewise, you can also share the benchmark tool by copying the link that’s provided and sharing it with your friends on social media. If someone else wants to check your results by clicking on that link, they’ll see a similar page as the one you got but without the share option.
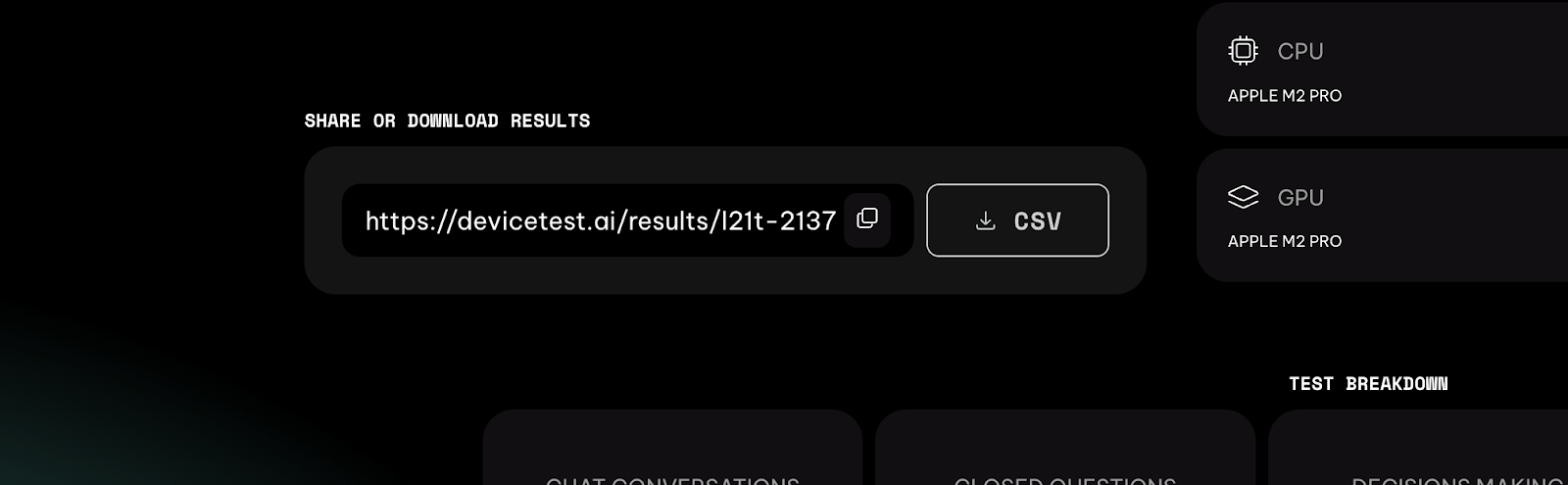
The data that is used in the test is only used to produce your test results, compare your computer to other users who take the test, and allow you to share the test results through your social media, if you wish to. No personal data is collected through the tool and no data is associated with specific users, IP addresses, or other identifiers.
If you would like more information on our data privacy practices, please see our Privacy Statement.
Download Opera to get access to the Benchmarking Tool
Thank you for sticking around until the end of the blog! If you want to access the benchmarking tool to check if your device is AI ready, download Opera Developer and head to this site. Share your results with your friends on social media and tag us – @Opera – if you want!

User comments
Turn ideas into action
Chat, create, and get things done with Opera Neon, the AI-powered browser that researches, builds, and acts for you.




You deserve a better browser
Opera's free VPN, Ad blocker, and Flow file sharing. Just a few of the must-have features built into Opera for faster, smoother and distraction-free browsing designed to improve your online experience.