Opera One Developer becomes the first browser with built-in local LLMs – ready for you to test
Share





Hello there,
Using an LLM or Large Language Model is a process that typically requires data being sent to a server. Local LLMs are different, as they allow you to process your prompts directly on your machine without the data you’re submitting to the local LLM leaving your computer.
Today, as part of our AI Feature Drops program, we are adding experimental support for 150 local LLM variants from ~50 families of models to our browser. This marks the first time local LLMs can be easily accessed and managed from a major browser through a built-in feature. Among them, you will find:
- Llama from Meta
- Vicuna
- Gemma from Google
- Mixtral from Mistral AI
- And many families more
The models are available from today on in the developer stream of Opera One.
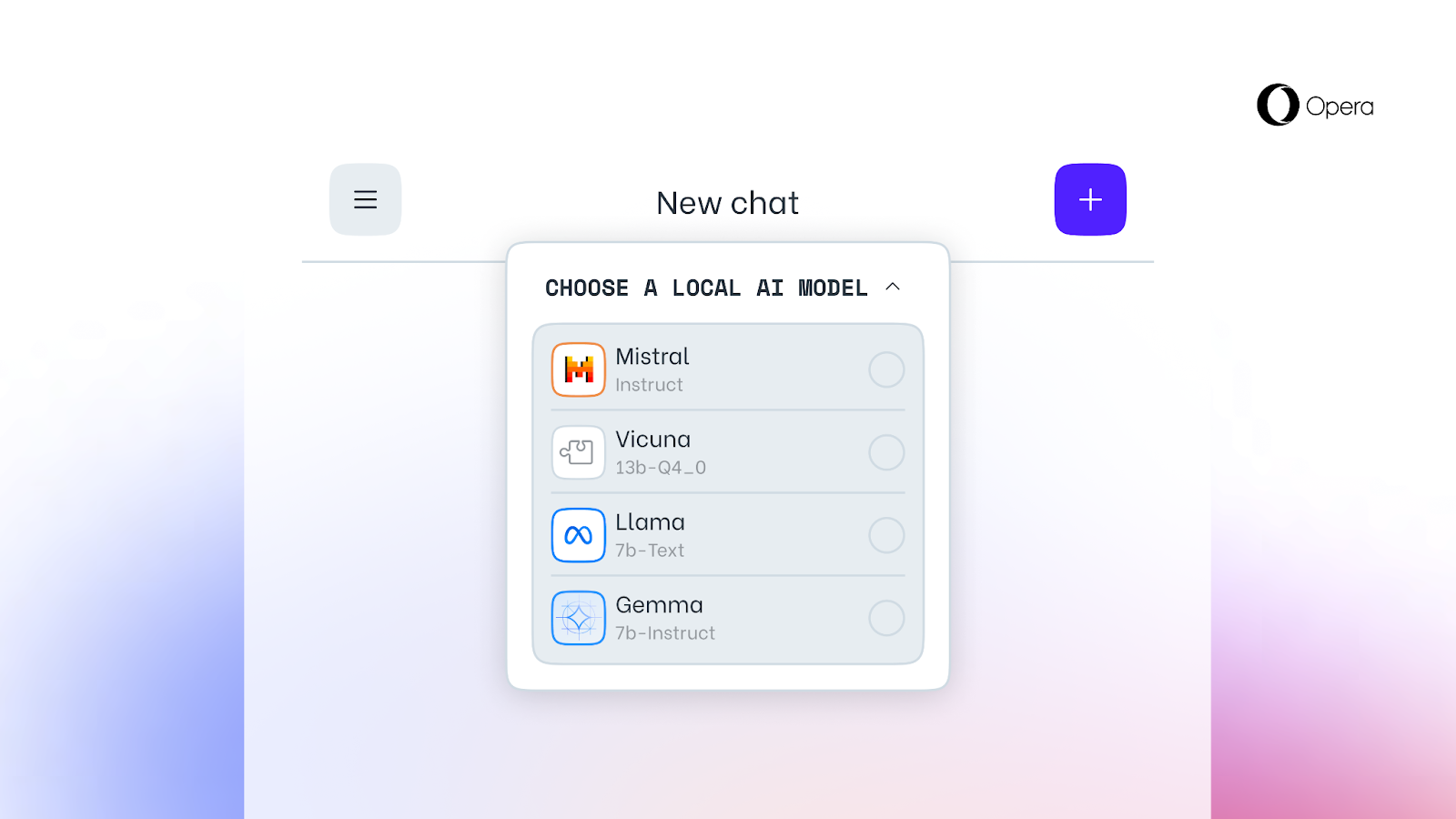
Using Local Large Language Models means users’ data is kept locally, on their device, allowing them to use AI without the need to send information to a server. We are testing this new set of local LLMs in the developer stream of Opera One as part of our AI Feature Drops Program, which allows you to test early, often experimental versions of our AI feature set.
As of today, the Opera One Developer community is getting the opportunity to select the model they want to process their input with, which is quite beneficial to the early adopter community that might have a preference for one model over another. This is so bleeding edge, that it might even break. But innovation wouldn’t be fun without experimental projects, would it?
Testing local LLMs in Opera Developer

Did we get your attention yet? To test the models, you have to upgrade to the newest version and do the following:
- Open the Aria Chat side panel (as before)
- On the top of the chat there will be a drop-down saying “Choose local mode”
- Click “Go to settings”
- Here you can search and browse which model(s) you want to download. Download e.g GEMMA:2B-INSTRUCT-Q4_K_M which is one of the smaller and faster models by clicking on the download button to the right
- After downloading is complete click the menu button on the top left and start a new chat
- On the top of the chat there will be a drop-down saying “Choose local mode”
- Select the model you just downloaded
- Type in a prompt in the chat, the local model will answer
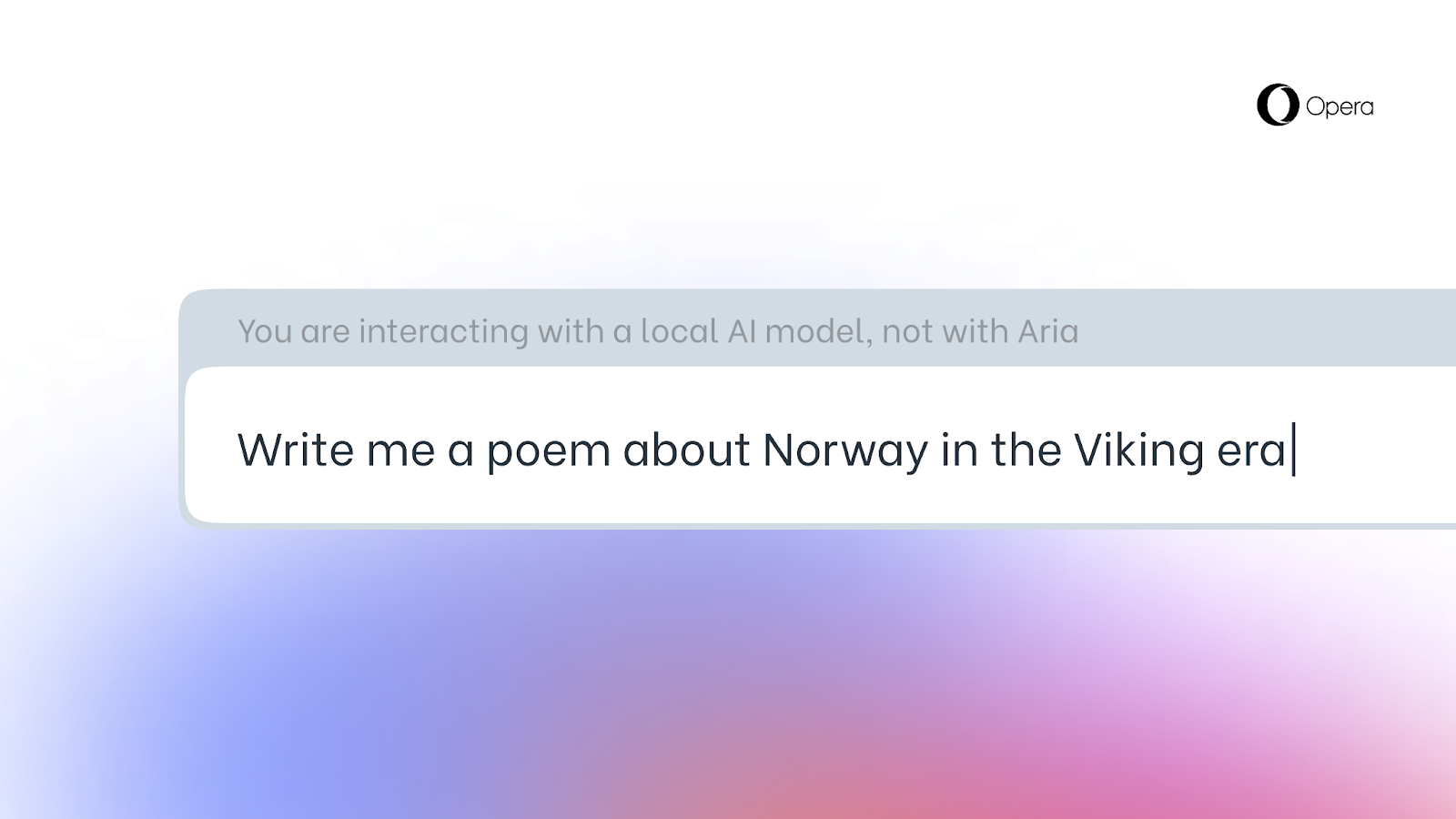
Choosing a local LLM will then download it to your machine. Please beware that each one of them requires between 2-10 GB of local storage space and that a local LLM is likely to be considerably slower in providing output than a server-based one as it depends on your hardware’s computing capabilities. The local LLM will be used instead of Aria, Opera’s native browser AI until you start a new chat with Aria or simply switch Aria back on.
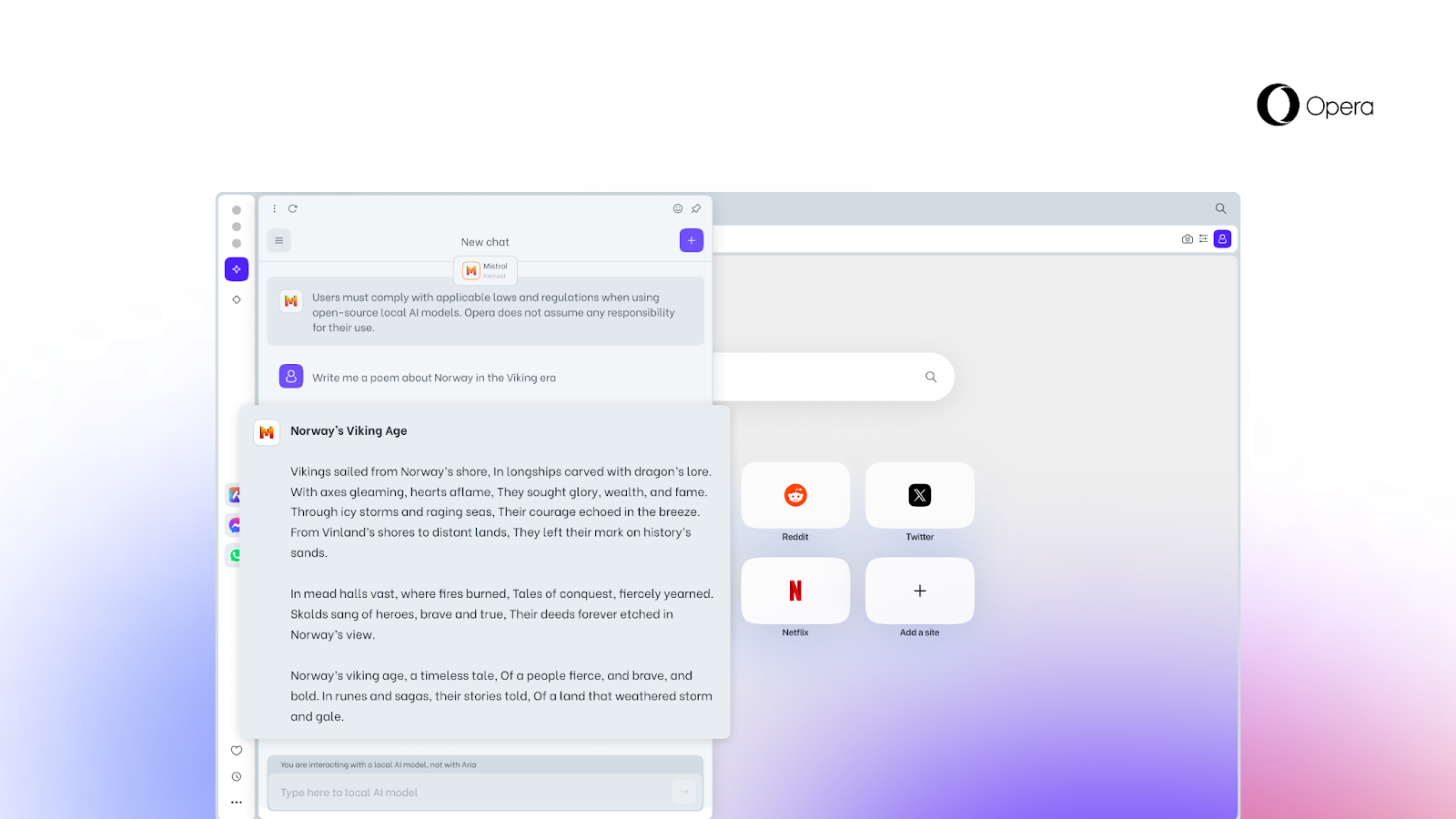
With this feature, we are starting to explore some potential future use cases. What if the browser of the future could rely on AI solutions based on your historic input while containing all of the data on your device? Food for thought. We’ll keep you posted about where these explorations take us.
To download Opera One Developer, click here
Interesting local LLMs to explore
Some interesting local LLMs to explore include Code Llama, an extension of Llama aimed at generating and discussing code, with a focus on expediting efficiency for developers. Code Llama is available in three versions: 7, 13, and 34 billion parameters. It accommodates numerous widely-used programming languages such as Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash, among others.
Variations:
– instruct – fine-tuned to generate helpful and safe answers in natural language
– python – a specialized variation of Code Llama further fine-tuned on 100B tokens of Python code
– code – base model for code completion
Phi-2, released by Microsoft Research, is a 2.7B parameter language model that demonstrates outstanding reasoning and language understanding capabilities. Phi-2 model is best suited for prompts using Question-answering, chat, and code formats.
Mixtral is designed to excel at a wide range of natural language processing tasks, including text generation, question answering, and language understanding. Key benefits: performance, versatility, and accessibility.
We will of course keep adding more interesting models as they appear in the AI community.

User comments
Turn ideas into action
Chat, create, and get things done with Opera Neon, the AI-powered browser that researches, builds, and acts for you.



You deserve a better browser
Opera's free VPN, Ad blocker, and Flow file sharing. Just a few of the must-have features built into Opera for faster, smoother and distraction-free browsing designed to improve your online experience.