Fuzzing HTTP Proxies: Privoxy, Part 1
Share




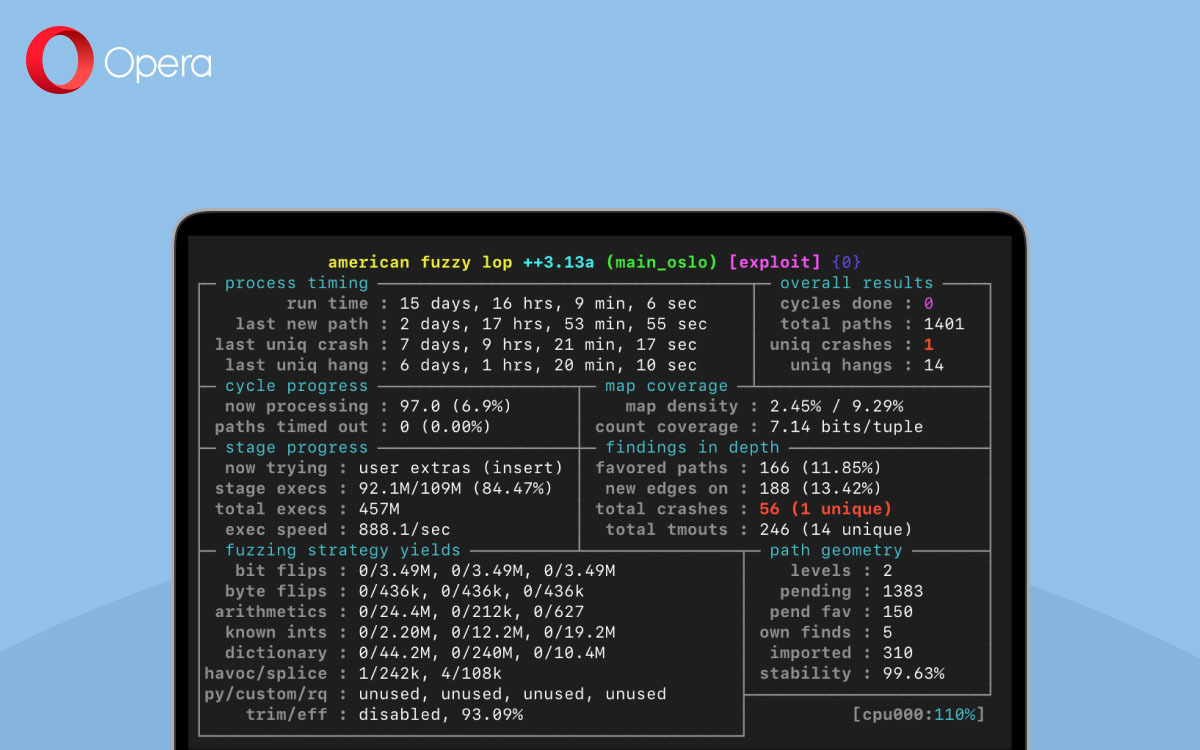
Here at Opera, we’re always looking for ways to improve the browsing experience of our users with speed and usability. Perhaps more importantly though, we also look for ways to improve users’ privacy and security.
While we continuously work to maintain the security of our own products, we keep in mind that other products with similar services are also an important part of the web-browsing ecosystem. Our core values and beliefs center around the entire ecosystem, not just Opera products, providing an experience that is secure for all users.
To achieve this, we’ve recently begun an internal initiative to audit the security of open-source proxies used for privacy and security. Along with this, we have also decided to create a series of blog posts in which we examine the flaws we’ve discovered, as well as how we found them, and their implications.
Our Plan For Securing HTTP Proxies
While there are various proxies available on the internet, we were inspired by the common setup which entails the Squid caching proxy in front of the privacy-aspiring Privoxy software.
Privoxy: A Privacy-Focused Proxy
In today’s post, we will be exploring the security of Privoxy, as it comprises the smallest, and easiest to understand, codebase. By examining the security of Privoxy, we can take a look at a simple (naive) HTTP proxy, which we will later pivot to a more full-fledged proxy, like Squid
During our tests, we discovered 6 severe vulnerabilities affecting Privoxy:
- Buffer overflow in pcre_compile() – CVE-2021-20276
- DoS in Config Gateway Request – CVE-2021-20217
- DoS in Config Gateway Request 2 – CVE-2021-20272
- DoS in Config Gateway Edit – CVE-2021-20273
- Buffer Overflow in Chunked Body Parsing – CVE-2021-20275
- Null Pointer Dereference in SOCKS Connection – CVE-2021-20274
The majority of the bugs found were in Privoxy’s internal “configuration gateway”, which allows for users to change different Privoxy settings from the browser. These vulnerabilities were not found in previous fuzzing campaigns because the testing had focused on specific functionality rather than being heuristic.
Background
Firstly, some information about Privoxy. It was first released in 2001 and is Free Open Source Software (FOSS), licensed with GNU GPLv2. Historically, Privoxy was the go-to software for entry into the TOR network due to its ability to translate HTTP headers for usage by upstream SOCKS proxies. Before the days of the Tor Browser, Tor was bundled with Privoxy. Even today, the Tor Project recommends Privoxy software.
The project is currently maintained by Fabian Keil who, in 2015, gave a talk on automatically finding bugs in software using the FreeBSD operating system. In that presentation, he discussed how he included, with only 1,000 lines of changes, a framework for automated security testing of Privoxy – fuzzing.
Privoxy’s Functionality
As mentioned, Privoxy is not an overly complicated program. While it can be used for a large range of different tasks and fine-tuning of different privacy-enhancing techniques, its source code is elegantly written between less than 30-files and contains less than 30,000-lines of C code.
In his 2015 talk, Keil outlined how he introduced new functionality to Privoxy which allowed for concentrated fuzzing in each of these areas. By creating a ”fuzzing mode” which could be switched on during compilation, it allows for a command-line switch to be used, exposing the internal functions of each of these functionalities, with arbitrary inputs.
Privoxy’s Fuzzing Mode
While Keil’s presentation focused on the AFL fuzzer, we decided to use the currently maintained AFL++ fuzzer. In addition to being a fuzzer, it also acts as a wrapper for the clang compiler.
Once the compilation of Privoxy in fuzzing mode is complete, different inputs can be passed to Privoxy’s internal functions as easily as
./privoxy --no-daemon --fuzz [fuzzing_type]
Some valid “fuzzing_type” values are “client-request”, “client-header”, and “server-response”. In the first two cases, “client-header” is a more concentrated type of fuzzing than “client-request” – that is to say, “client-header” fuzzing is a subset of “client-request” fuzzing.
How Privoxy Works
A generalized view of Privoxy’s functionality is shown below.
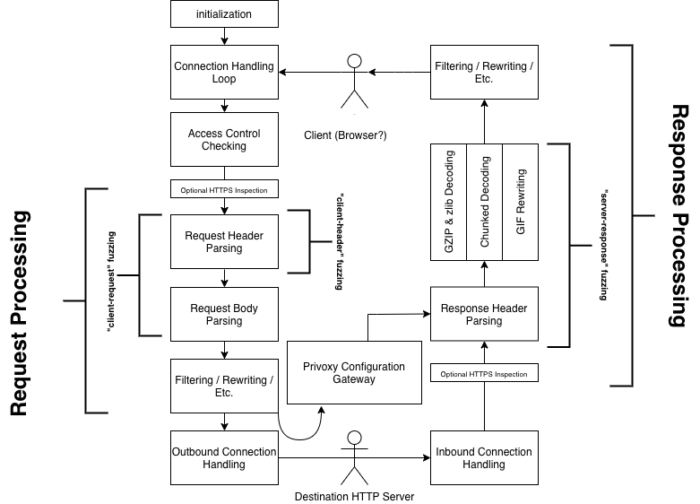
As we can see, “Request Processing” includes “Request Header Parsing”, “Request Body Parsing”, and “Filtering / Rewriting / Etc.” However, the “client-request” fuzzing mode only covers two of these sections of code. There is also no fuzzer which ever hits the code related to the Privoxy Configuration Gateway.
While this has the benefit of being able to quickly detect bugs in precise areas of code, it has the downside of missing bugs that rely on other operations before and after that section of the code.
Take for example, the following pseudo-code:
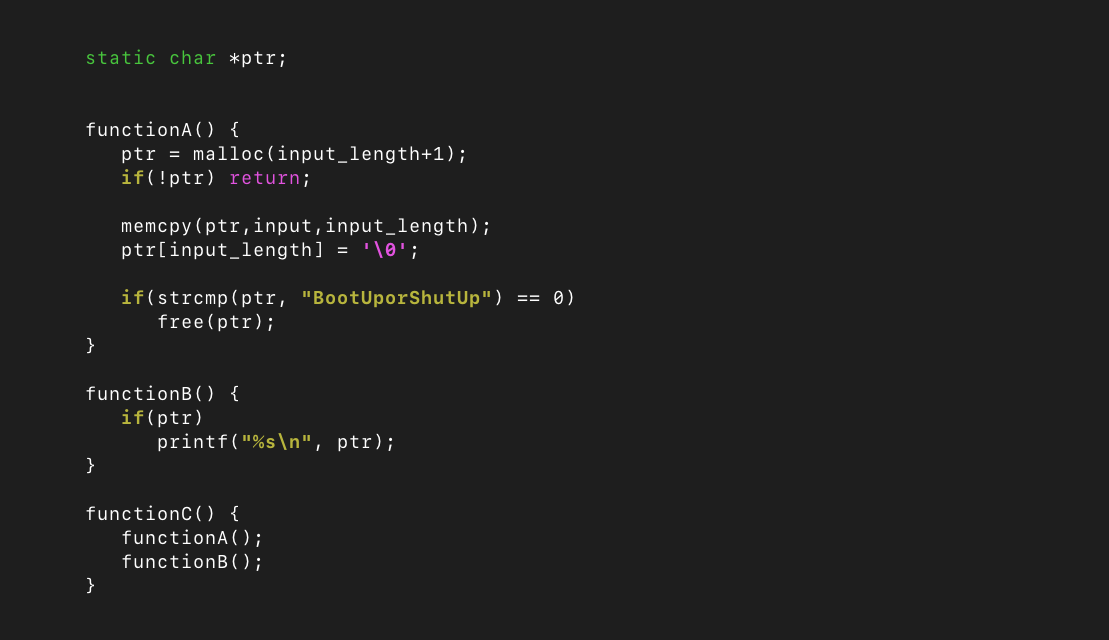
We can see that if we were to simply fuzz functionA(), there would be no issue found. Similarly, fuzzing functionB() would not be an issue by itself, because ptr is initialized as null and thus the function will do nothing.
However, if we were to fuzz functionC(), and the input was exactly “BootUporShutUp”, the obvious use-after-free vulnerability would occur, as the memory allocated to ptr would be freed in functionA() before the pointer was passed to printf() in functionB().
Improving Fuzzing of Privoxy
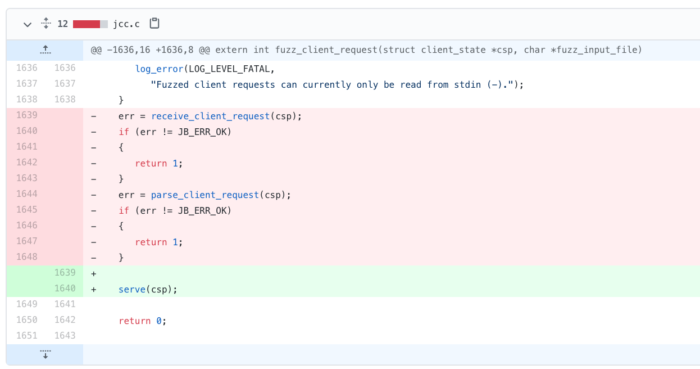
Going back to our diagram, our goal is to fuzz everything described in “Request Processing”, “Response Processing”, and “Privoxy Configuration Gateway”, using a single input. The original fuzz_client_request() function fuzzes the receive_client_request() and parse_client_request() functions, which, in Privoxy-terms, does the initial parsing of a request’s headers and body.
In a normal Privoxy setup, these two functions are usually called by the function chat(): a function which is 1000-lines long. That means we are “missing” 1000-lines of code because we are too low on the call stack. chat() itself is called by the serve() function, which is the highest on the call stack except for main(), in a normally-run Privoxy instance.
Therefore, with a simple one-line change of fuzz_client_request(), we instead begin fuzzing the serve() function, vastly improving the amount of unique code we are executing. This also means that once a request is parsed, a response is expected, and if available, will be parsed too
However, the question is now: if we have read all the fuzzing input from stdin to be dealt with by the request processing, how do we read new data to be dealt with by the response processing?
Splitting Inputs Into Two
When Privoxy wants to “read” from a connection, it uses file descriptors in the read_socket() function. Among other things, this function does the following (with fd=0 in fuzzing mode):
ret = (int)read(fd, buf, (size_t)len);For a fuzzer to be able to create – and Privoxy to be able to interpret – an input which corresponds to both a request and a response, we use a so-called “magic byte” – represented by the letter “ø” (or in hex, F8) – to separate the two. For example, an input may look like this:
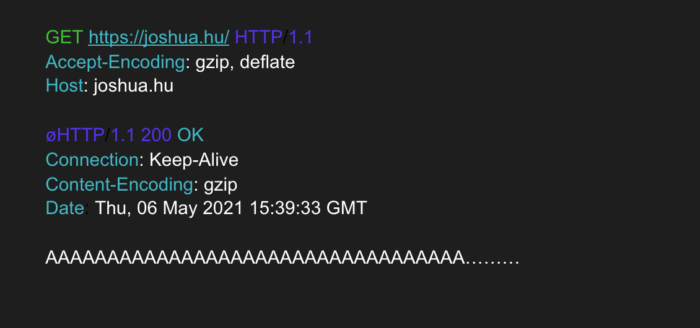
which contains both a request and a response, separated by a magic byte.
The next issue is how to get Privoxy to read only up to our “magic byte” when it tries to receive a request; then continue reading when it tries to read a response.
Reading a Split-Input in C
One way to read an input up until a specific character is to use the function read() on the stream 1-byte at a time, checking whether the 1-byte is our “magic byte”. This has the benefit that it is extremely easy to program. However, read() is a system call, meaning it is very slow. To test how quickly (or slowly) this method works, we timed how long it took to parse 2-MegaBytes’ worth of data.
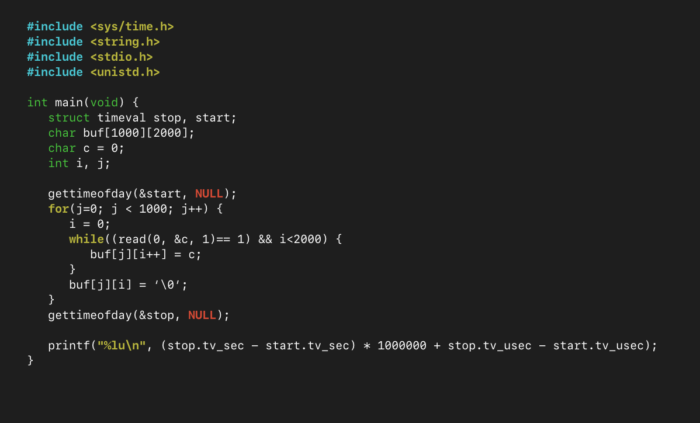
We ran this program with 2-MegaBytes of input from stdin, 100 times, to get a good sample size of how long the process takes: 1.39-seconds on average. That’s very slow. This is because read() needs to open stdin; buffer one-byte; then close the stream – two million times.
So while this method works, we need a way to open stdin; buffer several bytes without removing them from the stream; read that buffer one-byte-at-a-time; then close stdin.
To achieve this, we look to stdio.h, which provides FILE types to access the standard streams, rather than file descriptors. From stdio.h’s man page:
Since FILEs are a buffering wrapper around UNIX file descriptors, the same underlying files may also be accessed using the raw UNIX file interface, that is, the functions like read(2) and lseek(2).
stdio(3) – https://man7.org/linux/man-pages/man3/stdio.3.html
This means we can use the stdin FILE, which is a buffering wrapper for the raw file descriptors of the standard streams. As such, we now rewrite our code as the following (note: fgetc() reads the first character from a FILE):
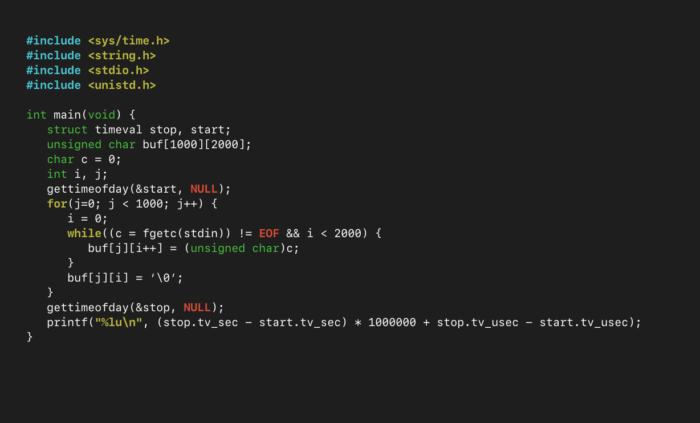
Once again, running this code 100 times and taking the average, the time it takes to fill in the character buffers is just 0.0160-seconds. That’s nearly a 90-fold improvement. This can be made even faster by using the fgetc_unlocked() function, which is the same as fgetc(), but is not thread-safe.
Reading Split Input in Privoxy
Given our new-found knowledge of how to quickly read data from stdin one-character at a time, we incorporate this into Privoxy’s code. We make this change in the read_socket() function.
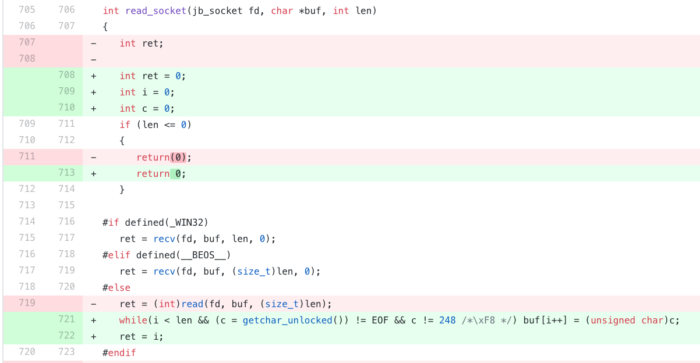
This will now read data until the “magic byte”, or the end of the stream (EOF). Consequently, when the read_socket() function is called for the first time, it will only read the “request” part of the input. On the second call to the function, it will read the “response” part.
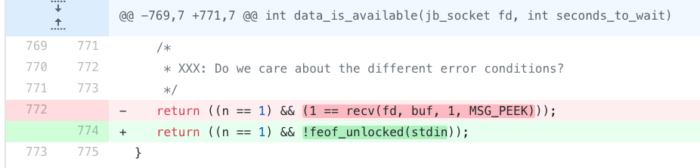
With this done, we now need to make a minor change in how Privoxy detects whether data has been “received” from a client or server. Since Privoxy normally uses “real” sockets, it uses the function recv() to peek into the contents of a file descriptor. This is handled in the data_is_available() function of Privoxy, which calls recvd(fd,buf,1,MSG_PEEK) to determine whether there is at least 1-byte of data available.
As we have established, we cannot peek into a stream like stdin, so instead we check whether the FILE stdin is empty or not using feof_unlocked(), which tests whether a stream is at the end of its file or not.
Other changes made to Privoxy’s code can be found here[0], here[1], and here[2].
Finding Valid Inputs for Fuzzing
Now that we have set up Privoxy to be able to be fuzzed as a “full system”, the next step is coming up with some valid inputs that AFL++ can use for fuzzing.
Because HTTP uses some formatting for its headers, we cannot just run the fuzzer with random input and hope it generates something meaningful. Instead, we take advantage of w3c’s HTTP/1.1-testing website, which provides tests (normally for browsers) in the form of different pages that a user can request.
We send a simple request using Netcat to the server, and record its output. We then combine a request and a response into a single file:
printf "GET / HTTP/1.1\r\nHost: Test.com\r\n\r\n\xF8" > input
printf "GET /HTTP/ChunkedScript HTTP/1.1\r\nHost: jigsaw.w3.org\r\n\r\n" | nc jigsaw.w3.org 80 >> input
Now the file “input” contains both a request and a response, separated by \xF8 (ø). We repeat this on different pages to generate a good set of corpora. Now we’re off! Let’s start fuzzing:
Vulnerabilities Found
We have now done everything we can to:
- Make Privoxy run as similarly to a “normally run” Privoxy daemon as possible, with a single user-supplied input
- Be able to encode an HTTP request and an HTTP response in a single input
- Make fuzzing as fast as possible.
Over a total of 84-cores and 1-week of fuzzing, we discovered 6 high-severity vulnerabilities: 3 denial-of-service vulnerabilities due to assertions, 2 buffer overflows, and 1 null pointer dereference.
Discussion on DoS Vulnerabilities Found
The majority of the bugs found were within the “Privoxy Configuration Gateway”. This gateway is a web-accessible panel that allows a user to change Privoxy’s settings without having direct access to the server on which Privoxy runs. On most Privoxy setups, it’s accessible in the browser by navigating to http://p.p/ or http://config.privoxy.org/. When accessing these pages, Privoxy detects that the user wants to access its configuration gateway, and handles them internally rather than sending the requests upstream.
The three of the denial-of-service vulnerabilities are all easy to trigger by requesting an “invalid” page (note: CVE-2021-20273 is only triggerable if Privoxy is in “off” mode):
| CVE-2021-20217 | http://config.privoxy.org/?1&0 |
| CVE-2021-20218 | http://config.privoxy.org/show-url-info?url=%0A0 |
| CVE-2021-20273 | http://config.privoxy.org/send-banner?type=r |
The issue with these three bugs is that, despite the gateway being an “internal” service, an external website can create the requests needed to cause Privoxy to crash. For example, a website can embed an image on a page using the URI http://config.privoxy.org/?1&0 – sure, it cannot read the contents (or cause any edits or actions to happen), but it can cause a browser to make the request. This could be used to crash any user’s Privoxy instance.
These three vulnerabilities were caused by assertions, rather than invalid memory accesses, and thus could not be used for anything other than denial-of-service (denying access for a webpage to any user of a proxy – legitimate or not – could be a very lucrative use-case). While assertions are a useful tool in programming which confirms that a program is working as intended, the overzealous usage of them can cause vulnerabilities like CVE-2021-20218. In that case, the assertion was simply removed, because Privoxy could continue to function normally. Similar overzealous assertions (which at the time of testing, could not be disabled) can be found within the source code of Privoxy, like the following:
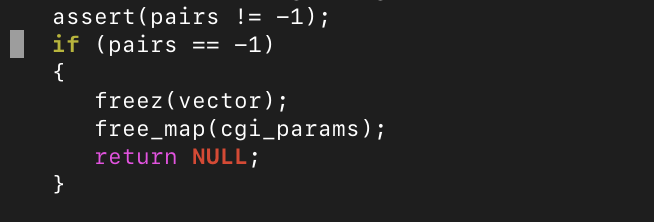
Other Vulnerabilities Found
Until recently, Privoxy provided the source code (for static compilation) of PCRE3 which, if configured at compilation-time, could be used over a dynamically linked PCRE library.
It was found that a very specific request (not provided in this post) made to the Privoxy Configuration Gateway could be used to trigger an invalid memory read and write (CVE-2021-20276). While this bug is not in Privoxy itself, it seems that there are no other reports of the bug easily found in the PCRE code. A fix was provided for the sake of Privoxy, and in the next version of Privoxy, the static PCRE code was completely removed.
A 2-byte buffer overflow was also found in the way Privoxy handled chunked body transfers, which could not be picked up in the direct fuzzing ‘chunked-transfer-encoding’ mode (CVE-2021-20275).
Other non-security bugs were picked up too, such as undefined behavior, uninitialized memory reading (with no security implications), and two bugs related to Privoxy’s “fuzzing mode” code.
Justifying Split Input Fuzzing
So far, we have seen bugs that are not dependent on the splitting of one input into multiple parts: all of them could be detected by simply reading one input using the higher call stack which we implemented. However, we did identify one vulnerability in how Privoxy handles upstream SOCKS proxy responses, which relies on the multiple-in-one input parsing we have created.
Privoxy has a “socks” fuzzing mode, which can be used to fuzz how upstream SOCKS handling is performed. The code related to this is fairly simple, and fuzzing in this mode using the standard Privoxy code yields no results. However, this fuzzing mode misses an important aspect of Privoxy’s SOCKS handling. To understand how SOCKS handling works in Privoxy, the following diagram is given.
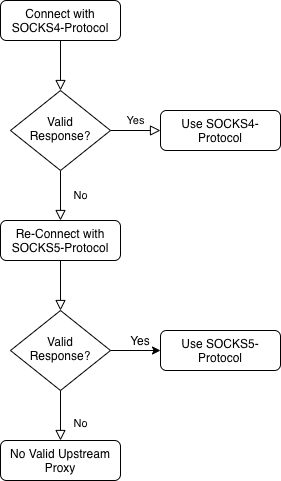
As we can see, Privoxy is not configured with a specific version of the SOCKS protocol in mind, so it guesses that the upstream server is SOCKS4 at first. If it does not receive a valid response, it then tests SOCKS5 before making a final decision. The issue here is that in fuzzing mode, all the input is read upon the first “connection” (i.e. reading of the fuzzing input), and thus the “response” upon re-testing for SOCKS5 is always empty. By splitting the input into multiple parts, our altered Privoxy can first read the response for SOCKS4 testing, then read a second response for SOCKS5 testing. This ended up discovering CVE-2021-20274: a null pointer dereference in the socks5_connect() function.
Confirming Fuzzing Yields
Finally, to confirm that we have fuzzed Privoxy to the best of our ability, we used afl-cov (which is a wrapper for lcov) to generate a coverage report, found here. In it, we can observe any lines of code that have not been executed for all the inputs that AFL++ has generated. For example, we might see some line of code that parses the URI of a request and checks it against some special value. If we don’t provide a “hint” to that special value, it will take the fuzzer a long time to eventually “guess” the special value, and we will miss the code associated with that value.
In our case, we can see that most of the code which is not executed is related to configuration parsing, out-of-memory error handling (such as malloc() failing), and network/socket handling.
With 80% of the functions within Privoxy’s codebase being covered during our fuzzing campaign – all from the combination of single input files – we are confident that Privoxy has been fuzzed well enough.
Conclusion
During our fuzzing of Privoxy, we discovered 6 vulnerabilities, and 5 non-security-related bugs. By extending Privoxy’s “fuzzing framework” with unconventional code changes which not only break portability but border on outright programming hacks because we were interested in finding bugs “at any cost”, we were able to identify flaws that a concentrated fuzzing of individual functions could not.
By allowing the partial parsing of a fuzzing input with a separator, we were able to fuzz Privoxy more similarly to how it would be run in a real-world setting: an HTTP request would be replied to with an HTTP response.
Thank you
If you’ve made it this far into this blog post, then I want to thank you for reading, and I hope you’ll join me in future posts where I’ll be looking at how fuzzing can be used in unconventional ways to find bugs and vulnerabilities, and how I found nearly 50-vulnerabilities in the Squid caching proxy.
Acknowledgments
I would like to thank Fabian Keil for his continued support and development of the Privoxy software, and for his speedy fixes for the bugs identified in this post. I would also like to thank the developers of AFL++ for the work they do, as well as my managers for the equipment used for fuzzing.

User comments
You deserve abetter browser
Faster, safer and smarter than default browsers. Fully-featured for privacy, security, and so much more.






You deserve a better browser
Opera's free VPN, Ad blocker, and Flow file sharing. Just a few of the must-have features built into Opera for faster, smoother and distraction-free browsing designed to improve your online experience.